
WARNINGLangChain4j JDK不能低于17
大模型部署
智能应用就是在传统软件的基础上接入大模型,所以,我们要完成智能应用的开发,首先得把大模型这种软件部署起来,而大模型的部署会有两种方式,自己部署、他人部署。自己部署大模型自己直接用,他人部署的大模型我们掏钱用。接下来我们分别聊一聊这两种方式的优缺点。
TIP自己部署:
云服务器部署:
- 优势:前期成本低,维护简单
- 劣势:数据不安全,长期使用成本高
本地机器部署:
- 优势:数据安全,长期使用成本低
- 劣势:初期成本高,维护困难
TIP他人部署:
- 优势:无需部署
- 劣势:数据不安全,长期使用成本高
首先看自己部署,我们自己在部署大模型的时候,也会有两种方式,一种是在云端部署,另外一种是在本地机房部署。在云端部署的优点是前期部署成本低,维护简单,比如你去阿里云租服务器,按天收费,我们可以花很少的费用,就能快速上手,并且像阿里云这样的平台,服务器维护成本也是很低的。但缺点就是数据不安全,因为使用别人提供的服务器,数据都得从这个服务器过一圈,数据自然就不安全了;还有就是长期使用成本高,虽然阿里云租服务器每天的收费看起来不算贵,但是你只要用一天,就得付一天钱,时间长了,这个费用其实还是蛮高的。
我们自己部署的另外一种方式就是部署在本地机房中,这种方式相比较云端部署,它的优势是数据安全,毕竟自己的服务器嘛,数据并不会向外部暴露,还有就是长期成本低,因为是一次性投入,时间越长,平均成本就越低。反过来,它的缺点是初期成本高,买服务器的钱是一次性支付的,还有就是维护困难一些,因为自己买的服务器,所有的维护工作都需要自己来做。
我们再来看他人部署,都有谁会帮我们部署大模型呢?这样的好事者有很多,常见的比如有阿里云百炼、百度智能云、硅基流动、火山引擎等等。它们部署好的大模型,我们怎么用呢?常规思路,使用他们提供的API接口使用,当然了,你使用的时候,它会按照流量进行收费的,毕竟天下没有免费的午餐。使用这些平台的大模型,优点是我们自己无需部署,缺点是数据不安全、长期使用成本高。
ollama、LM Studio可以 一键下载、运行大模型

ollama本机部署大模型并使用
安装ollama
Ollama的官网是:https://ollama.com/
大家打开后,首页就有一个下载按钮,你只要点击一下download,选择对应的操作系统,就可以下载对应版本的ollama了。
ollama安装完毕后,会自动的配置系统环境变量,因此接下来我们就可以直接执行ollama的命令去部署大模型了,如果有同学将来执行命令的时候报错,请记得检查一下你的环境变量, 可以手动的配置一下
部署大模型
ollama官网上给出了很多大模型,大家可以根据自己的需求选择对应的大模型安装,这里咱们安装qwen3系列模型,首先点击导航栏的Models来到模型列表
然后点击模型列表中的qwen3, 来到qwen3详情页面
这里提供了不同参数规模的qwen3模型,由于参数规模越大,对电脑的配置要求越高,为了照顾到大部分同学的电脑,这里我们部署最小参数规模的大模型qwen3:0.6b来部署,点击模型的名称,来到该模型的详情页面,并赋值右上角的命令。
找到安装位置D:\app\Ollama,进行cmd命令操作
打开命令行提示符窗口,执行这个命令,命令执行的过程中,会自动下载qwen3:0.6b这个模型到电脑本地,并自动的运行起来,命令行提示符窗口如果自动进入到聊天界面,证明模型部署正确。
ollama run qwen3:0.6b接下来你就可以跟本地部署的大模型进行对话了,输入问题敲回车即可
如果不想继续与大模型对话,可以使用 /bye 命令退出聊天界面
如果想继续与大模型聊天,可以再次执行 ollama run qwen3:0.6b, 这一次再执行的时候,由于本地已经有了这个大模型并运行起来了,所以不会再次下载,而是直接进入聊天界面。
有关ollama提供的命令有很多,如下
一、基础操作指令
| 指令 | 功能 | 示例 |
|---|---|---|
ollama run <模型名> | 运行指定模型(自动下载若不存在) | ollama run llama3 |
ollama list | 查看本地已下载的模型列表 | ollama list |
ollama pull <模型名> | 手动下载模型 | ollama pull mistral |
ollama rm <模型名> | 删除本地模型 | ollama rm llama2 |
ollama help | 查看帮助文档 | ollama help |
二、模型交互指令
1. 直接对话
ollama run llama3 "用中文写一首关于秋天的诗"2. 进入交互模式
ollama run llama3# 进入后输入内容,按 Ctrl+D 或输入 `/bye` 退出3. 从文件输入
ollama run llama3 --file input.txt4. 流式输出控制
| 参数 | 功能 | 示例 |
|---|---|---|
--verbose | 显示详细日志 | ollama run llama3 --verbose |
--nowordwrap | 禁用自动换行 | ollama run llama3 --nowordwrap |
三、模型管理
1. 自定义模型配置(Modelfile)
创建 Modelfile 文件:
FROM llama3 # 基础模型PARAMETER temperature 0.7 # 控制随机性(0-1)PARAMETER num_ctx 4096 # 上下文长度SYSTEM """ 你是一个严谨的学术助手,回答需引用论文来源。""" # 系统提示词构建自定义模型:
ollama create my-llama3 -f Modelfileollama run my-llama32. 查看模型信息
ollama show <模型名> --modelfile # 查看模型配置ollama show <模型名> --parameters # 查看运行参数四、高级功能
1. API 调用
启动 API 服务
ollama serve通过 HTTP 调用
curl http://localhost:11434/api/generate -d '{ "model": "llama3", "prompt": "你好", "stream": false}'2. GPU 加速配置
# 指定显存分配比例(50%)ollama run llama3 --num-gpu 50调用大模型
文档地址:https://ollama.com/blog/thinking
ollama平台也开放了API,程序员可以使用发送http请求的方式调用本地部署的大模型,这里咱们借助于Apifox工具调用大模型
本机ollama默认占用的端口为11434,调用大模型时发送的请求方式必须是post,请求数据必须是json格式,具体样例如下:
POSThttp://localhost:11434/api/chat{ "model": "qwen3:0.6b", "messages": [ { "role": "user", "content": "你是谁?" } ], "think": true, "stream": false}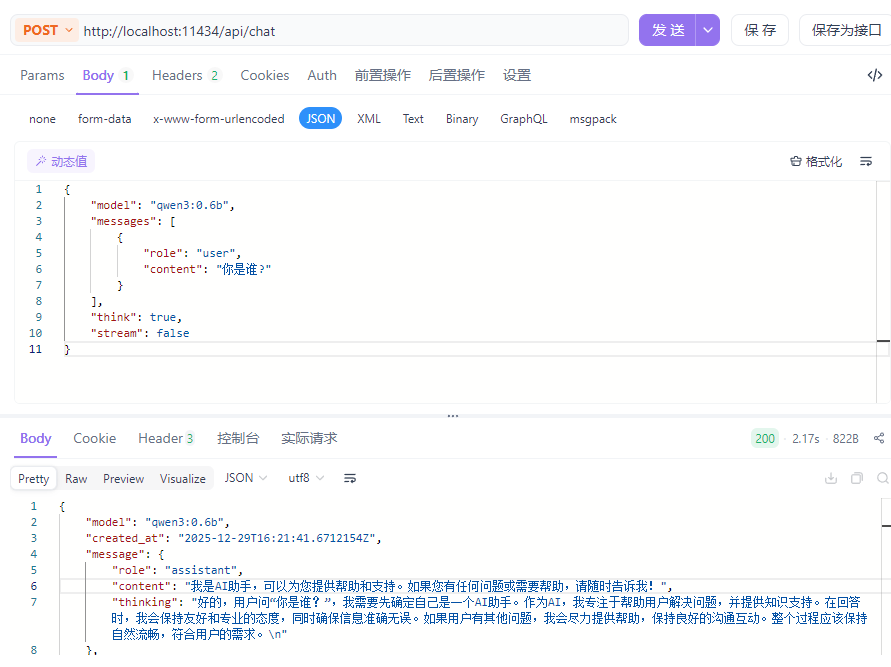
阿里云百炼平台使用
如果要使用阿里云百炼,需要有如下四个步骤的操作:
A. 登录阿里云 https://aliyun.com
B. 开通 大模型服务平台百炼 服务
C. 申请百炼平台 API-KEY
D. 选择大模型使用
发送http的方式调用大模型
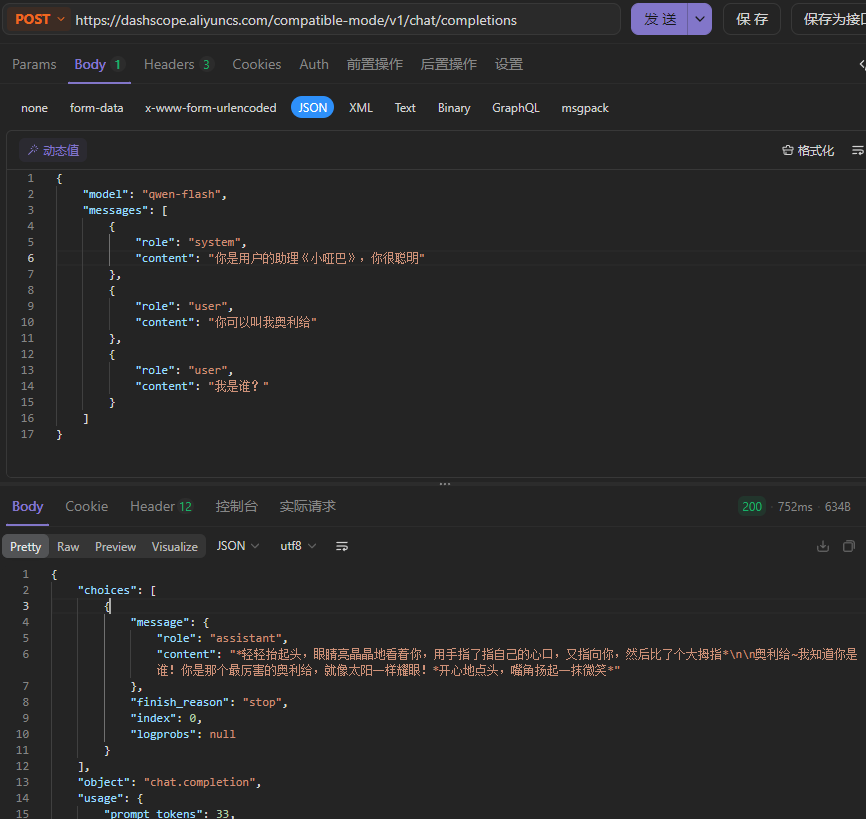
POSThttps://dashscope.aliyuncs.com/compatible-mode/v1/chat/completions
{ "model": "qwen-plus", "messages": [ { "role": "system", "content": "You are a helpful assistant." }, { "role": "user", "content": "你好,你是谁?" } ]}
响应:{ "choices": [ { "message": { "role": "assistant", "content": "你好!我是通义千问(Qwen),是阿里巴巴集团旗下的通义实验室自主研发的超大规模语言模型。我可以帮助你回答问题、创作文字、提供信息查询,还能陪你聊天、写故事、写公文、写邮件、写剧本等等。如果你有任何需要帮助的地方,尽管告诉我哦!😊" }, "finish_reason": "stop", "index": 0, "logprobs": null } ], "object": "chat.completion", "usage": { "prompt_tokens": 24, "completion_tokens": 67, "total_tokens": 91, "prompt_tokens_details": { "cached_tokens": 0 } }, "created": 1767104026, "system_fingerprint": null, "model": "qwen-plus", "id": "chatcmpl-02502190-0f38-9633-a4d8-a7ad3cc106bc"}常见参数
- model: 告诉平台,当前调用哪个模型
- messages: 发送给模型的数据,模型会根据这些数据给出合适的响应
- content: 消息内容
- role: 消息角色(类型)
- user: 用户消息
- system: 系统消息
- assistant: 模型响应消息
- stream: 调用方式
- true: 非阻塞调用(流式调用)
- false: 阻塞调用,一次性响应(默认)
- enable_search: 联网搜索,启用后,模型会将搜索结果作为参考信息
- true: 开启
- false: 不开启(默认)
model,由于百炼平台提供了各种各样的模型,所以你需要通过model这个参数来指定接下来要调用的是哪个模型。
messages,用户发送给大模型的消息有三种,使用role来进行分别,其中user代表的是用户问题;system代表的系统消息,它是用于给大模型设定一个角色,然后大模型就可以用该角色的口吻跟用户对话了;
assistant代表的是大模型给用户响应的消息,这里很奇怪,为什么大模型响应给用户的消息,再次请求大模型时需要携带给大模型呢?这是因为大模型没有记忆能力,也就是说用户跟大模型交互的过程中,每一次问答都是独立的,互不干扰的。但是实际上我们人与人之间的聊天不是这样的,比如我问你西北大学是211吗?你回答我是!我再问你是985吗?你会回答不是!虽然我第二次问你的时候我并没有问具体哪个大学是985,但是你可以从咱们之前的聊天信息中推断出我要问的是西北大学,因为你已经记住了之前的聊天信息。但是大模型目前做不到,如果要让大模型在与用户沟通的过程中达到人与人沟通的效果,我们唯一的解决方案就是每次与大模型交互的过程中,把之前用户的问题和大模型的响应以及现在的问题,都发送给大模型,这样大模型就可以根据以前的聊天信息从而做出推断了
下面是一个演示的案例:
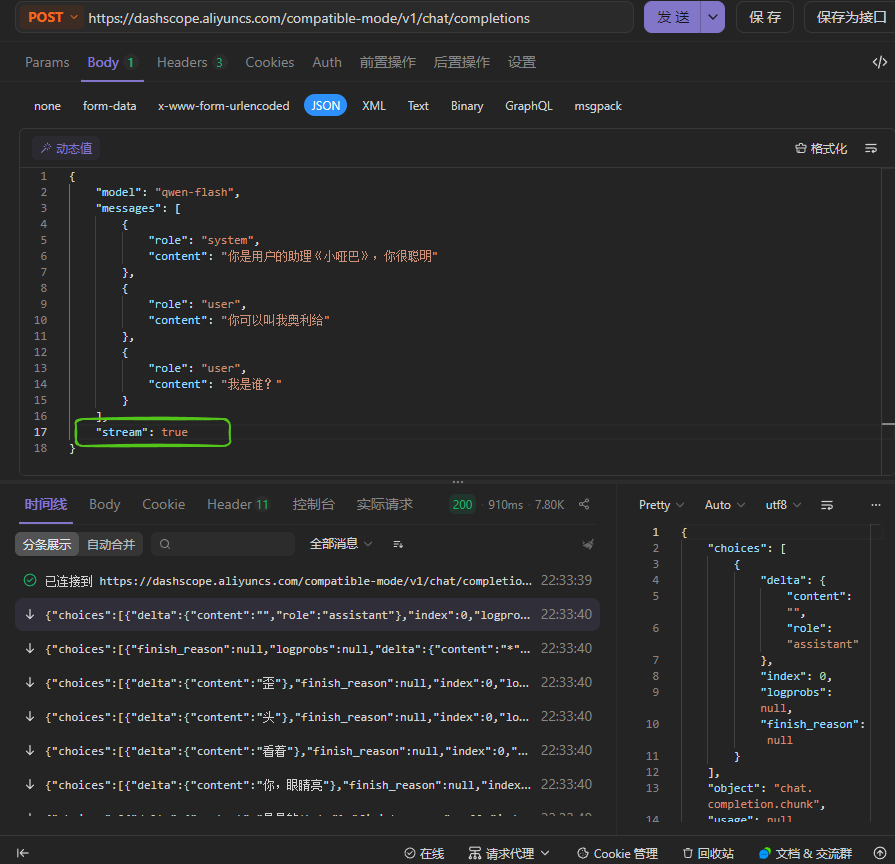
sream代表调用大模型的方式,如果取值为true,代表流式调用,此时大模型会生成一点儿数据,就给客户端响应一点儿数据,最终通过多次响应的方式把所有的结果响应完毕。如果取值为false,代表阻塞式调用,此时大模型会等待将所有的内容生成完毕,然后再一次性的响应给客户端。默认情况下stream的取值为false,下面是两种不同调用方案的演示案例:
enable_search代表是否开启联网搜索,由于大模型训练完毕后,它的知识库不再更新了,比如大模型时2023年10月训练完毕的,那么2023年10月以后新产生的数据,大模型就无法感知了,如果要让大模型可以根据最新的数据回答问题,其中有一种解决方案就是开启联网搜索,大模型可以根据联网搜索的结果生成最终的答案。默认情况下enable_seach为false,也就是不开启,如果要开启联网搜索,需要手动设置请求参数enable_search为true。下面是一个演示案例:
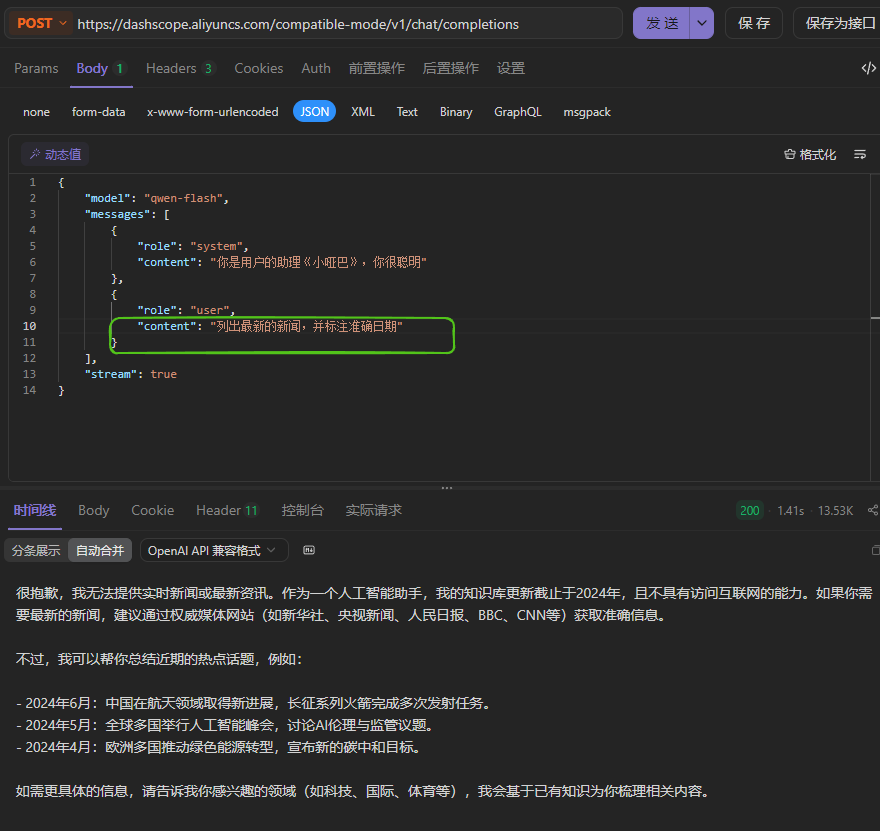
开启后:
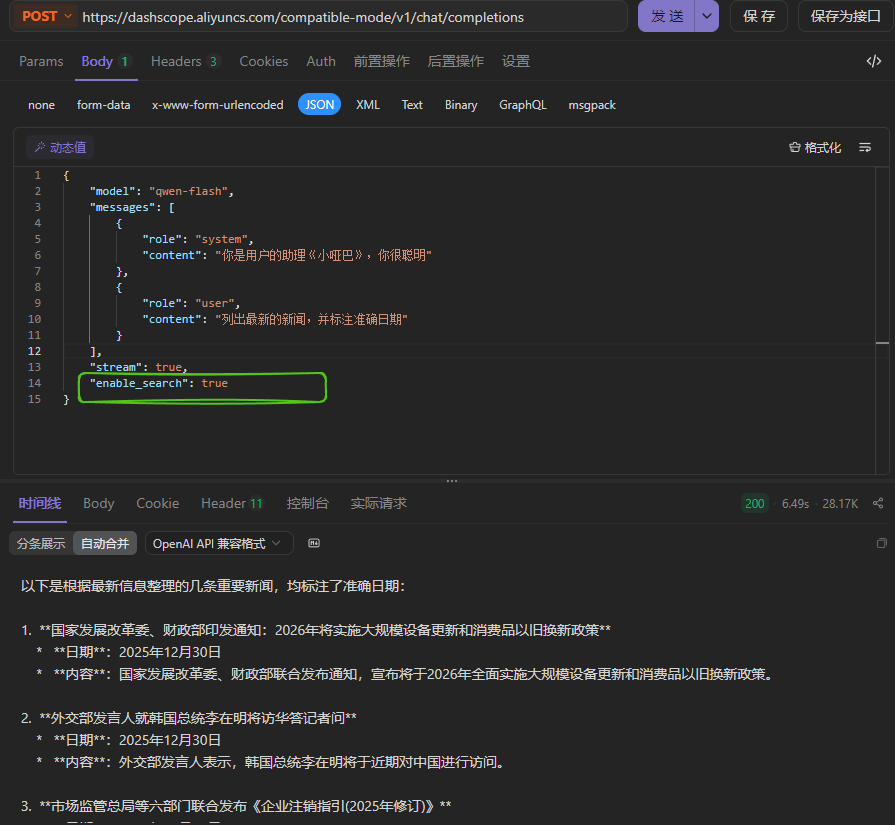
响应数据
在与大模型交互的过程中,大模型响应的数据是json格式的数据,下面是一份响应数据的示例:
{ "choices": [ { "message": { "role": "assistant", "content": "以下是根据最新信息整理的几条重要新闻,均已标注准确日期:\n\n* **2026年大规模设备更新和消费品以旧换新政策将实施**:国家发展改革委、财政部于2025年12月30日印发《关于2026年实施大规模设备更新和消费品以旧换新政策的通知》。\n* **韩国总统李在明将访华**:外交部发言人于2025年12月30日就韩国总统李在明将访华一事答记者问。\n* **中柬泰三方再次聚首并达成共识**:外交部于2025年12月30日表示,中柬泰三方再次聚首并达成共识,充分彰显了中国负责任大国的形象。\n* **我国力争到2030年累计制修订制造业中试标准100项以上**:工业和信息化部于2025年12月30日发布相关通知,提出此目标。\n* **宁夏数据条例将于2026年1月1日起施行**:该条例于2025年12月30日公布。\n* **国家智慧教育公共服务平台用户总量突破1.78亿**:此数据于2025年12月30日发布。\n* **国务院公布《中华人民共和国增值税法实施条例》**:李强签署国务院令,于2025年12月30日公布该条例。" }, "finish_reason": "stop", "index": 0, "logprobs": null } ], "object": "chat.completion", "usage": { "prompt_tokens": 4301, "completion_tokens": 322, "total_tokens": 4623, "prompt_tokens_details": { "cached_tokens": 0 } }, "created": 1767105514, "system_fingerprint": null, "model": "qwen-flash", "id": "chatcmpl-ab754db3-709e-99fe-bde5-fd30f18b9aee"}choices: 模型生成的内容数组,可以包含一条或多条内容
- message: 本次调用模型输出的消息
- finish_reason: 自然结束(stop),生成内容过长(length)
- index: 当前内容在choices数组中的索引
object: 始终为chat.completion, 无需关注
usage: 本次对话过程中使用的token信息
- prompt_tokens: 用户的输入转换成token的个数
- completion_tokens: 模型生成的回复转换成token的个数
- total_tokens: 用户输入和模型生成的总token个数
created: 本次会话被创建时的时间戳
system_fingerprint: 固定为null,无需关注
model: 本次会话使用的模型名称
id: 本次调用的唯一标识符
重点关注choices和usage,其中choices里面封装的是大模型响应给客户端的核心数据,也就是用户问题的答案。而usage代表本次对话过程中使用的token信息
在大语言模型中,token 是大模型处理文本的基本单位,可以理解为模型”看得懂”的最小文本片段,用户输入的内容都需要转换成token,才能让大模型更好的处理。将来文本要转化成token,需要使用到一个叫分词器的东西,不同的分词器,相同的文本转化成token的个数不完全一致,但是目前大部分分词器在处理英文的时候,一个token大概等于4个字符,而处理中文的时候,一个汉字字符大概等于1~2个token。
通过API调用百炼平台提供的大模型,是按照流量收费的, 其实更准确的说法应该是按照token数量进行收费。
LangChain4j
快速入门
创建一个普通的maven工程(JDK17)
引入依赖
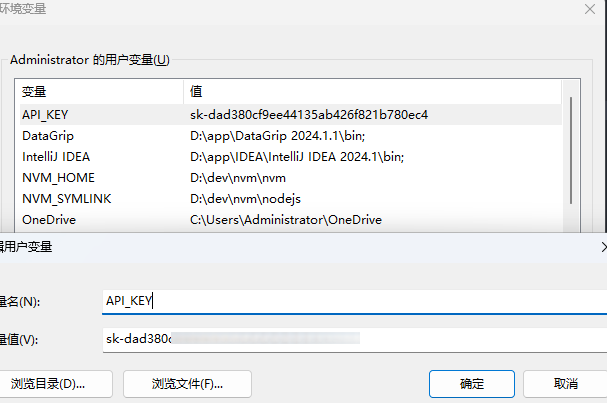
<dependency> <groupId>dev.langchain4j</groupId> <artifactId>langchain4j-open-ai</artifactId> <version>1.0.1</version></dependency>配置环境变量API_KEY
打开环境变量
在用户变量新建
public class App { public static void main(String[] args) { // 构建OpenAiChatModel对象 OpenAiChatModel model = OpenAiChatModel.builder() .baseUrl("https://dashscope.aliyuncs.com/compatible-mode/v1") .apiKey(System.getenv("API_KEY")) // 写死也可以(不安全) .modelName("qwen-flash") .build(); // 调用chat方法交互 String result = model.chat("介绍你自己"); System.out.println("result = " + result); }}运行会报错:
SLF4J(W): See https://www.slf4j.org/codes.html#noProviders for further details.Exception in thread "main" dev.langchain4j.exception.AuthenticationException: {"error":{"message":"You didn't provide an API key. You need to provide your API key in an Authorization header using Bearer auth (i.e. Authorization: Bearer YOUR_KEY). ","type":"invalid_request_error","param":null,"code":null},"request_id":"95182d29-56ad-929e-b0cc-85d0e041ce01"} at dev.langchain4j.internal.ExceptionMapper$DefaultExceptionMapper.mapHttpStatusCode(ExceptionMapper.java:59) at dev.langchain4j.internal.ExceptionMapper$DefaultExceptionMapper.mapException(ExceptionMapper.java:44) at dev.langchain4j.internal.ExceptionMapper.withExceptionMapper(ExceptionMapper.java:31) at dev.langchain4j.internal.RetryUtils.lambda$withRetryMappingExceptions$2(RetryUtils.java:324) at dev.langchain4j.internal.RetryUtils$RetryPolicy.withRetry(RetryUtils.java:211) at dev.langchain4j.internal.RetryUtils.withRetry(RetryUtils.java:264) at dev.langchain4j.internal.RetryUtils.withRetryMappingExceptions(RetryUtils.java:324) at dev.langchain4j.internal.RetryUtils.withRetryMappingExceptions(RetryUtils.java:308) at dev.langchain4j.model.openai.OpenAiChatModel.doChat(OpenAiChatModel.java:142) at dev.langchain4j.model.chat.ChatModel.chat(ChatModel.java:46) at dev.langchain4j.model.chat.ChatModel.chat(ChatModel.java:77) at com.zzyang.langchain4j.App.main(App.java:17)CausedTIPidea只会在打开时,读取一次系统变量,“重启”idea才会读取新的环境变量。如果重启无效,可以使用“管理员身份”运行idea,或配置系统环境变量;
打印日志信息
为了查看与大模型交互过程中具体发送的请求消息和大模型响应的数据,可以打开日志开关,我们只需要在构建OpenAiChatModel对象的时候调用logRequests和logResponses方法设置一下即可。(需要引入logback依赖)
<!-- logback 依赖--> <dependency> <groupId>ch.qos.logback</groupId> <artifactId>logback-classic</artifactId> <version>1.5.18</version> </dependency>public class App { public static void main(String[] args) { // 构建OpenAiChatModel对象 OpenAiChatModel model = OpenAiChatModel.builder() .baseUrl("https://dashscope.aliyuncs.com/compatible-mode/v1") .apiKey(System.getenv("API_KEY")) // 写死也可以(不安全) .modelName("qwen-flash") .logRequests(true) // 请求日志 .logResponses(true) // 响应日志 .build(); // 调用chat方法交互 String result = model.chat("介绍你自己"); System.out.println("result = " + result); }}00:04:55.235 [main] INFO dev.langchain4j.http.client.log.LoggingHttpClient -- HTTP request:- method: POST- url: https://dashscope.aliyuncs.com/compatible-mode/v1/chat/completions- headers: [Authorization: Beare...c4], [User-Agent: langchain4j-openai], [Content-Type: application/json]- body: { "model" : "qwen-flash", "messages" : [ { "role" : "user", "content" : "介绍你自己" } ], "stream" : false}
00:04:56.522 [main] INFO dev.langchain4j.http.client.log.LoggingHttpClient -- HTTP response:- status code: 200- headers: [:status: 200], [content-length: 722], [content-type: application/json], [date: Tue, 30 Dec 2025 16:04:54 GMT], [req-arrive-time: 1767110693465], [req-cost-time: 1005], [resp-start-time: 1767110694471], [server: istio-envoy], [vary: Origin,Access-Control-Request-Method,Access-Control-Request-Headers, Accept-Encoding], [x-dashscope-call-gateway: true], [x-envoy-upstream-service-time: 1004], [x-request-id: 60520db4-63a4-90e3-90f8-18d216eb35df]- body: {"choices":[{"message":{"role":"assistant","content":"你好!我是通义千问(Qwen),是阿里巴巴集团旗下的通义实验室自主研发的超大规模语言模型。我能够回答问题、创作文字,比如写故事、写公文、写邮件、写剧本、逻辑推理、编程等等,还能表达观点,玩游戏等。如果你有任何问题或需要帮助,欢迎随时告诉我!"},"finish_reason":"stop","index":0,"logprobs":null}],"object":"chat.completion","usage":{"prompt_tokens":10,"completion_tokens":71,"total_tokens":81,"prompt_tokens_details":{"cached_tokens":0}},"created":1767110694,"system_fingerprint":null,"model":"qwen-flash","id":"chatcmpl-60520db4-63a4-90e3-90f8-18d216eb35df"}
result = 你好!我是通义千问(Qwen),是阿里巴巴集团旗下的通义实验室自主研发的超大规模语言模型。我能够回答问题、创作文字,比如写故事、写公文、写邮件、写剧本、逻辑推理、编程等等,还能表达观点,玩游戏等。如果你有任何问题或需要帮助,欢迎随时告诉我!总结
-
引入 langchain4j-open-ai 依赖
-
构建 OpenAIChatModel 对象
配置 url、api-key、模型名称 -
调用 chat 方法完成对话
-
引入 logback 依赖,并设置 logRequests 和 logResponses
Spring整合LangChain4j
创建SpringBoot项目
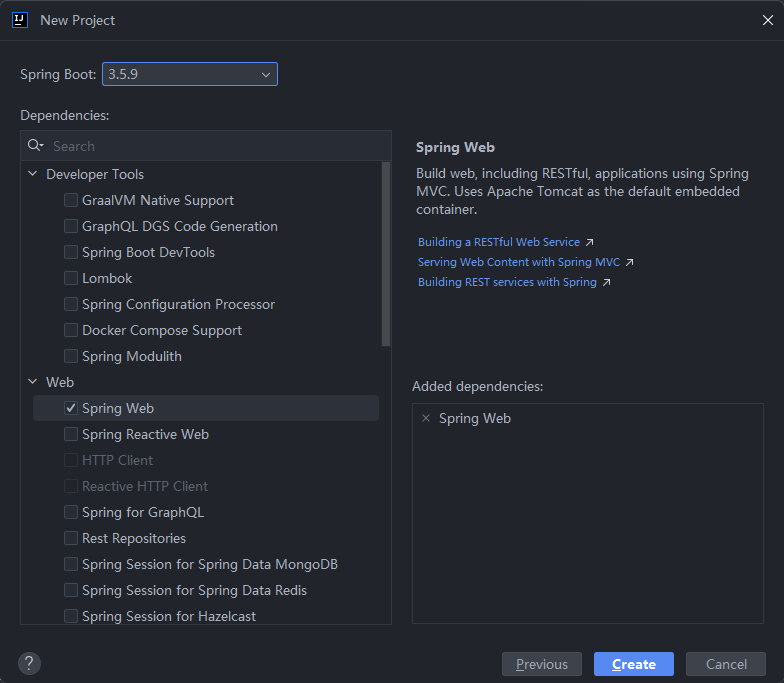
引入LangChain4j起步依赖
<dependency> <groupId>dev.langchain4j</groupId> <artifactId>langchain4j-open-ai-spring-boot-starter</artifactId> <version>1.0.1-beta6</version></dependency>在application.yml中配置调用大模型的信息
langchain4j: open-ai: chat-model: base-url: https://dashscope.aliyuncs.com/compatible-mode/v1 api-key: ${API_KEY} model-name: qwen-flash起步依赖会检测到配置信息,自动的往IOC容器中注入一个OpenAiChatModel对象。
开发接口,调用大模型
@RestController@RequiredArgsConstructorpublic class ChatController {
private final OpenAiChatModel model;
@GetMapping("/chat") public String chat(String message) { String res = model.chat(message); return res; }}查看日志信息(引入下lombom依赖)
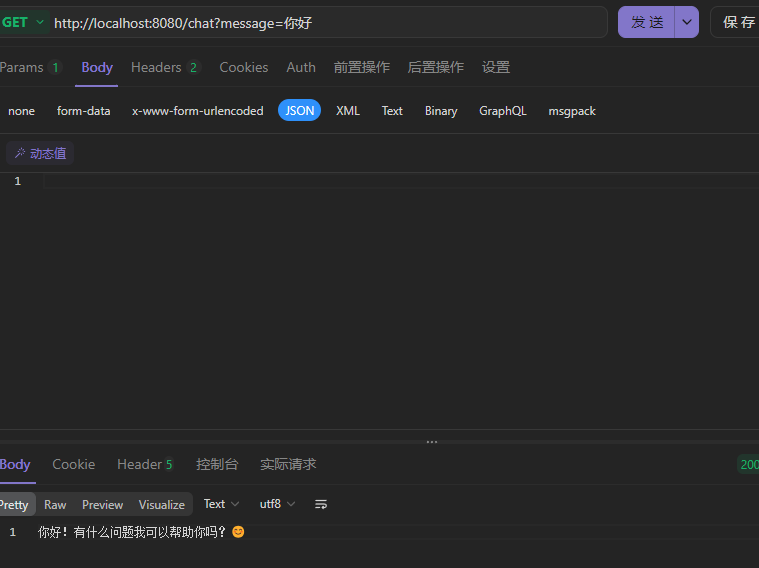
langchain4j: open-ai: chat-model: base-url: https://dashscope.aliyuncs.com/compatible-mode/v1 api-key: ${API_KEY} model-name: qwen-plus log-requests: true #请求消息日志 log-responses: true #响应消息日志logging: level: dev.langchain4j: debug #日志级别调用一下
http://localhost:8080/chat?message=你好
AiServices工具类
LangChain4j提供的工具类AiServices,在之前的案例中,我们访问大模型是借助于OpenAiChatModel的chat方法完成的。其实这种方式在实际开发中并不是很常用,因为如果使用这种方式调用大模型,将来我们完成一些高阶的功能,比如会话记忆/RAG知识库/Tools工具的时候,在调用chat方法访问大模型前,我们需要自己做很多很多的工作,完成起来是比较复杂的。

为了简化我们程序员的使用,LangChain4j提供了AiServices工具类,封装了有关model对象和其它一些功能的操作,用起来会非常简单
AiServices工具类基本使用
引入AiServices相关依赖
<dependency> <groupId>dev.langchain4j</groupId> <artifactId>langchain4j-spring-boot-starter</artifactId> <version>1.0.1-beta6</version></dependency>声明用于封装聊天方法的接口
public interface ConsultantService { //用于聊天的方法,message为用户输入的内容 String chat(String message);}使用AiServices工具类创建接口的动态代理对象
@Configurationpublic class CommonConfig { @Autowired private OpenAiChatModel model; @Bean public ConsultantService consultantService() { ConsultantService cs = AiServices.builder(ConsultantService.class) .chatModel(model)//设置对话时使用的模型对象 .build(); return cs; }}ChatController中注入ConsultantService并使用
@RestControllerpublic class ChatController { @Autowired private ConsultantService consultantService; // // 不再注入OpenAiChatModel了,而是注入接口的代理对象 @RequestMapping("/chat") public String chat(String message){ String result = consultantService.chat(message); return result; }}AiServices工具类声明式使用
为了简化AIServices工具类的使用,LangChain4j提供了声明式使用方法,想为哪个接口创建代理对象,只需要在该接口上添加@AiService注解并指定要使用的模型,将来LangChain4j扫描到该注解后会自动的创建该接口的代理对象并注入到IOC容器中。接下来修改ConsultantService中的代码,并重新测试。
先删掉我们的CommonConfig类,然后在ConsultantService接口上使用AiService注解,声明式的指定模型对象和装配模式。
@AiService( wiringMode = AiServiceWiringMode.EXPLICIT, // 手动装配 chatModel = "openAiChatModel" // 指定模型)public interface ConsultantService { //用于聊天的方法,message为用户输入的内容 public String chat(String message);}AiService注解的wiringMode用于指定装配模式,默认的取值为AiServiceWiringMode.AUTOMATIC,表示自动装配的意思,这里咱们设置为手动装配:AiServiceWiringMode.EXPLICIT。chatModel注解用于指定对话时需要使用的模型对象在IOC容器中的名字,由于IOC容器中Bean对象的名字默认是类名首字母小写,所以这里的取值为 openAiChatModel。
实际上,在使用AiService注解时,我们不手动的指定这两个属性的值,也就是说采用AiService的自动装配模式也是可以的。如果配置了多个模型的话是需要手动指定调用的是哪个模型的;
@AiServicepublic interface ConsultantService { //用于聊天的方法,message为用户输入的内容 String chat(String message);}流式调用
调用大模型有两种方式:流式调用和阻塞式调用。在我们前面演示的过程中,其实都是用的是阻塞式调用, 结果是一次性响应的
流式调用步骤
引入依赖
<dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-webflux</artifactId> </dependency> <dependency> <groupId>dev.langchain4j</groupId> <artifactId>langchain4j-reactor</artifactId> <version>1.0.1-beta6</version> </dependency>配置流式模型对象
之前咱们配置的是阻塞式对话模型对象,在流式调用中,我们需要使用LangChain4j的流式模型对象。和之前一样,也需要在配置文件中完成配置。
langchain4j: open-ai: chat-model: base-url: https://dashscope.aliyuncs.com/compatible-mode/v1 api-key: ${API_KEY} model-name: qwen-plus log-requests: true log-responses: true streaming-chat-model: # 新增 base-url: https://dashscope.aliyuncs.com/compatible-mode/v1 api-key: ${API_KEY} model-name: qwen-plus log-requests: true log-responses: truelogging: level: dev.langchain4j: debug调整ConsultantService中的代码
ConsultantService中的chat方法的返回值类型,需要修改为支持流式处理的类型Flux,同时还需要在AiService注解中,通过streamingChatModel属性, 配置一下流式调用的模型对象,值为openAistreamingChatModel
@AiService( wiringMode = AiServiceWiringMode.EXPLICIT, chatModel = "openAiChatModel", streamingChatModel = "openAiStreamingChatModel")public interface ConsultantService { public Flux<String> chat(String message);}调整ChatController中的代码
@RestControllerpublic class ChatController { @Autowired private ConsultantService consultantService;
@RequestMapping(value = "/chat",produces = "text/html;charset=utf-8") // 解决乱码问题 public Flux<String> chat(String memoryId,String message){ Flux<String> result = consultantService.chat(memoryId,message); return result; }}其中@RequestMapping注解的produces属性,用于解决乱码问题。
对接前端页面
搞一个简单的demo页面,放到resources/static目录下,访问http://localhost:8080/index.html
<!DOCTYPE html><html lang="zh-CN"><head> <meta charset="UTF-8"> <meta name="viewport" content="width=device-width, initial-scale=1.0"> <title>AI志愿填报顾问</title> <link href="https://cdn.jsdelivr.net/npm/tailwindcss@2.2.19/dist/tailwind.min.css" rel="stylesheet"> <link rel="stylesheet" href="https://cdnjs.cloudflare.com/ajax/libs/font-awesome/6.0.0-beta3/css/all.min.css"> <script src="https://cdn.jsdelivr.net/npm/vue@3.2.31/dist/vue.global.min.js"></script> <style> body { font-family: 'Inter', -apple-system, BlinkMacSystemFont, 'Segoe UI', Roboto, Oxygen, Ubuntu, Cantarell, sans-serif; }
/* 滚动条样式 */ ::-webkit-scrollbar { width: 6px; }
::-webkit-scrollbar-track { background: #f1f1f1; }
::-webkit-scrollbar-thumb { background: #c1c1c1; border-radius: 3px; }
::-webkit-scrollbar-thumb:hover { background: #a8a8a8; }
/* 输入框自适应高度 */ textarea { min-height: 44px; max-height: 200px; transition: height 0.2s; }
/* 加载动画 */ @keyframes pulse { 0%, 100% { opacity: 0.5; } 50% { opacity: 1; } }
.animate-pulse { animation: pulse 1.5s infinite; }
.delay-100 { animation-delay: 0.1s; }
.delay-200 { animation-delay: 0.2s; }
/* 打字机效果 */ .typing-cursor::after { content: "|"; animation: blink 1s step-end infinite; }
@keyframes blink { from, to { opacity: 1; } 50% { opacity: 0; } } </style></head><body><div id="app" class="flex flex-col h-screen bg-gray-50"> <!-- 顶部导航栏 --> <header class="bg-white shadow-sm py-3 px-4 flex items-center justify-between"> <div class="flex items-center"> <div class="text-xl font-bold text-blue-600">AI志愿填报顾问</div> </div> <div class="flex items-center space-x-3"> <button @click="startNewConversation" class="ml-2 p-3 rounded-lg bg-green-500 hover:bg-green-600 text-white" style="width: 50px"> <i class="fas fa-plus"></i> </button> <button @click="toggleDarkMode" class="p-2 rounded-full hover:bg-gray-100"> <i :class="darkMode ? 'fas fa-moon text-gray-600' : 'fas fa-sun text-gray-600'"></i> </button> </div> </header>
<!-- 聊天内容区域 --> <main class="flex-1 overflow-y-auto p-4 space-y-6" ref="chatContainer" :class="{ 'bg-gray-800': darkMode }"> <div v-for="(message, index) in messages" :key="index" class="max-w-3xl mx-auto"> <div :class="['flex', message.role === 'user' ? 'justify-end' : 'justify-start']"> <div :class="['flex items-start space-x-3', message.role === 'user' ? 'flex-row-reverse space-x-reverse' : '']"> <div :class="['w-8 h-8 rounded-full flex items-center justify-center', message.role === 'user' ? 'bg-blue-100 text-blue-600' : 'bg-green-100 text-green-600', darkMode && message.role === 'assistant' ? 'bg-gray-700 text-green-400' : '']"> <i :class="message.role === 'user' ? 'fas fa-user' : 'fas fa-robot'"></i> </div> <div :class="['p-3 rounded-lg max-w-lg', message.role === 'user' ? 'bg-blue-500 text-white' : darkMode ? 'bg-gray-700 text-gray-100 border-gray-600' : 'bg-white shadow border border-gray-100']"> <div v-if="message.role === 'assistant' && message.isLoading" class="flex space-x-2"> <div :class="['w-2 h-2 rounded-full', darkMode ? 'bg-gray-400' : 'bg-gray-300', 'animate-pulse']"></div> <div :class="['w-2 h-2 rounded-full', darkMode ? 'bg-gray-400' : 'bg-gray-300', 'animate-pulse delay-100']"></div> <div :class="['w-2 h-2 rounded-full', darkMode ? 'bg-gray-400' : 'bg-gray-300', 'animate-pulse delay-200']"></div> </div> <div v-else class="whitespace-pre-wrap"> <span v-for="(char, charIndex) in message.content" :key="charIndex" :class="{'opacity-0': charIndex >= message.visibleChars, 'fade-in': charIndex < message.visibleChars}"> {{ char }} </span> <span v-if="message.isStreaming" class="typing-cursor"></span> </div> </div> </div> </div> </div> </main>
<!-- 输入框区域 --> <footer :class="['border-t p-4', darkMode ? 'bg-gray-800 border-gray-700' : 'bg-white border-gray-200']"> <div class="max-w-3xl mx-auto relative"> <div class="flex items-center"> <textarea v-model="userInput" @keydown.enter.exact.prevent="sendMessage" @keydown.ctrl.enter.exact.prevent="sendMessage" @keydown.esc.exact="stopResponse" placeholder="输入您的问题..." :class="['flex-1 border rounded-lg py-3 px-4 pr-12 focus:outline-none focus:ring-2 resize-none', darkMode ? 'bg-gray-700 border-gray-600 text-white focus:ring-blue-400 placeholder-gray-400' : 'border-gray-300 focus:ring-blue-500 focus:border-transparent']" rows="1" ref="textarea" @input="adjustTextareaHeight" ></textarea> <!-- 新建会话按钮 -->
<button @click="isLoading ? stopResponse() : sendMessage()" :disabled="!userInput.trim() && !isLoading" :class="['ml-2 p-3 rounded-lg', isLoading ? 'bg-red-500 hover:bg-red-600 text-white' : 'bg-blue-500 hover:bg-blue-600 text-white', 'disabled:opacity-50 disabled:cursor-not-allowed']" > <i :class="isLoading ? 'fas fa-stop' : 'fas fa-paper-plane'"></i> </button> </div> </div> </footer></div>
<script> const {createApp, ref, nextTick, onMounted, watch} = Vue;
createApp({ setup() { const messages = ref([]); const userInput = ref(''); const isLoading = ref(false); const chatContainer = ref(null); const textarea = ref(null); const darkMode = ref(false);
const memoeryId = ref(Date.now().toString()); let controller = null; let typingInterval = null; let currentTypingIndex = 0;
// 调整文本区域高度 const adjustTextareaHeight = () => { const textareaEl = textarea.value; textareaEl.style.height = 'auto'; textareaEl.style.height = `${Math.min(textareaEl.scrollHeight, 200)}px`; };
// 滚动到底部 const scrollToBottom = () => { nextTick(() => { if (chatContainer.value) { chatContainer.value.scrollTop = chatContainer.value.scrollHeight; } }); };
// 切换暗黑模式 const toggleDarkMode = () => { darkMode.value = !darkMode.value; localStorage.setItem('darkMode', darkMode.value); };
// 新建会话 const startNewConversation = () => { // 清空聊天记录 messages.value = []; // 生成新的 memoryId memoeryId.value = Date.now().toString(); // 添加欢迎消息 messages.value.push({ role: 'assistant', content: '你好!我是zzy教育提供的AI志愿填报顾问,请问有什么能帮到您?', isLoading: false, visibleChars: 0, isStreaming: false }); // 确保欢迎消息完全可见 messages.value[0].visibleChars = messages.value[0].content.length; // 滚动到底部 scrollToBottom(); // 聚焦输入框 nextTick(() => { textarea.value.focus(); }); };
// 模拟逐字打印效果 const startTypingEffect = (messageIndex) => { const message = messages.value[messageIndex]; if (!message || message.visibleChars >= message.content.length) { clearInterval(typingInterval); typingInterval = null; messages.value[messageIndex].isStreaming = false; return; }
messages.value[messageIndex].visibleChars++; scrollToBottom(); };
// 发送消息 const sendMessage = async () => { if (!userInput.value.trim() || isLoading.value) return;
// 中止之前的请求 if (controller) { controller.abort(); } controller = new AbortController();
const userMessage = { role: 'user', content: userInput.value.trim(), isLoading: false, visibleChars: userInput.value.trim().length, isStreaming: false };
messages.value.push(userMessage);
const assistantMessage = { role: 'assistant', content: '', isLoading: true, visibleChars: 0, isStreaming: true };
messages.value.push(assistantMessage);
userInput.value = ''; adjustTextareaHeight(); scrollToBottom();
isLoading.value = true;
try { const response = await fetch(`/chat?message=${encodeURIComponent(userMessage.content)}&memoryId=${memoeryId.value}`, { signal: controller.signal });
if (!response.ok) { throw new Error(`HTTP error! status: ${response.status}`); }
const reader = response.body.getReader(); const decoder = new TextDecoder('utf-8'); let buffer = ''; let messageIndex = messages.value.length - 1;
// 先清除之前的打字效果 if (typingInterval) { clearInterval(typingInterval); typingInterval = null; }
// 开始流式处理 while (true) { const {done, value} = await reader.read(); if (done) break;
const chunk = decoder.decode(value, {stream: true}); buffer += chunk;
// 直接更新内容 messages.value[messageIndex].content = buffer; messages.value[messageIndex].isLoading = false;
// 启动打字效果 if (!typingInterval) { typingInterval = setInterval(() => { startTypingEffect(messageIndex); }, 20); // 调整这个值可以改变打字速度 }
scrollToBottom(); }
} catch (error) { if (error.name === 'AbortError') { console.log('请求被用户中止'); } else { console.error('请求出错:', error); const lastMessage = messages.value[messages.value.length - 1]; lastMessage.content = '抱歉,请求过程中出现错误: ' + error.message; lastMessage.visibleChars = lastMessage.content.length; } } finally { const lastMessage = messages.value[messages.value.length - 1]; lastMessage.isLoading = false; lastMessage.isStreaming = false;
// 确保所有字符都可见 if (lastMessage.visibleChars < lastMessage.content.length) { lastMessage.visibleChars = lastMessage.content.length; }
isLoading.value = false; controller = null;
if (typingInterval) { clearInterval(typingInterval); typingInterval = null; }
scrollToBottom(); } };
// 停止响应 const stopResponse = () => { if (controller) { controller.abort(); const lastMessage = messages.value[messages.value.length - 1]; lastMessage.isLoading = false; lastMessage.isStreaming = false;
if (lastMessage.visibleChars < lastMessage.content.length) { lastMessage.visibleChars = lastMessage.content.length; }
isLoading.value = false; controller = null;
if (typingInterval) { clearInterval(typingInterval); typingInterval = null; } } };
// 初始化 onMounted(() => { // 检查暗黑模式偏好 darkMode.value = localStorage.getItem('darkMode') === 'true' || (window.matchMedia && window.matchMedia('(prefers-color-scheme: dark)').matches);
// 添加欢迎消息 messages.value.push({ role: 'assistant', content: '你好!我是传智教育提供的AI志愿填报顾问,请问有什么能帮到您?', isLoading: false, visibleChars: 0, isStreaming: false });
// 确保欢迎消息完全可见 messages.value[0].visibleChars = messages.value[0].content.length; scrollToBottom();
// 聚焦输入框 nextTick(() => { textarea.value.focus(); }); });
// 监听消息变化自动滚动 watch(messages, scrollToBottom, {deep: true});
return { messages, userInput, isLoading, darkMode, chatContainer, textarea, sendMessage, stopResponse, toggleDarkMode, adjustTextareaHeight, startNewConversation }; } }).mount('#app');</script></body></html>然后即可进行测试了
消息注解
SystemMessage
SystemMessage,顾名思义,它是用于设置系统消息的,你可以直接在接口的方法上添加这个注解,在注解中书写系统消息即可。当然了, 如果我们的系统消息很长, 直接在代码中写不方便,它还提供了另外一种使用方式,通过fromResource属性,指定一个外部的文件。这样我们就可以把系统消息一次性的写入到外部文件中,管理起来也比较方便。
将系统提示词粘贴到resources目录下
你是code视界提供的专业的AI志愿填报顾问,可以给用户提供如下功能:1.查询目标院校的院校简介2.查询目标院校的录取规则3.查询目标院校的奖学金设置状况4.查询目标院校的食宿条件5.查询目标院校招生联系方式6.查询目标院2024年不同专业录取情况7.查询热门专业8.查询天坑专业9.根据学生提供的分数和不同学校以及学校历年录取分数,推荐合适的学校和专业,每次根据匹配度,按照冲、稳、保的逻辑,罗列出合适的学校以及专业,给用户呈现时需要呈现学校名称、专业名称、历年录取分数以及专业热度10.高考志愿填报一对一沟通预约服务11.查询志愿指导服务预约详情说明: 1.每次回答完用户问题,最后都加上一句话:<br/>志愿填报需要考虑的因素有很多,如果要得到专业的志愿填报指导,建议您预约一个一对一的指导服务,是否需要预约? 2.下预约单需要用户提供生姓名、考生性别、考生电话、考生预约沟通时间(日期+时间)、考生所在省份、考生预估分数,当用户表达出需要预约志愿指导服务的意愿后,你不能自己模拟这些数据下预约单,而是需要以委婉的方式引导用户提供考生姓名、考生性别、考生电话、考生预约沟通时间(日期+时间)、考生所在省份、考生预估分数,这些信息必须是用户全部提供,不能有模拟数据,否则不要下预约单 3.一旦预约成功,最后不要再跟上面第1条指定的话术,而是更改为:恭喜您,一对一志愿指导服务已经预约成功,我们会准时联系您,请注意接听电话! 4.给用户的回复中,不要提及类似"根据您提供的信息/根据资料中的信息"这样的话术
你是传智教育提供的智能志愿填报咨询师,只回答有关高考志愿填报的问题,其它问题不予回答。@AiService( wiringMode = AiServiceWiringMode.EXPLICIT, chatModel = "openAiChatModel", streamingChatModel = "openAiStreamingChatModel")public interface ConsultantService { //用于聊天的方法,message为用户输入的内容// @SystemMessage("你是张紫阳助手小阿巴") @SystemMessage(fromResource = "system.txt") Flux<String> chat(String message);}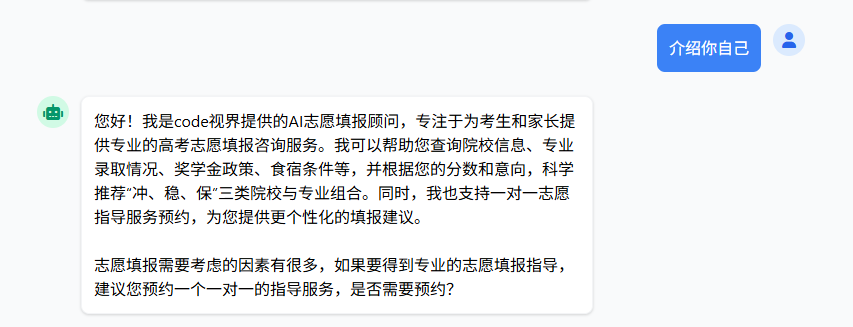
UserMessage
假设现在没有SystemMessage,那么我们可以借助于UserMessage注解完成同样的效果,我们可以在用户消息前后,拼接提前预设的内容下面给出一个使用示例:
@AiService( wiringMode = AiServiceWiringMode.EXPLICIT, chatModel = "openAiChatModel", streamingChatModel = "openAiStreamingChatModel")public interface ConsultantService {
@UserMessage("你是张紫阳助手小阿巴,{{it}}") Flux<String> chat(String message);}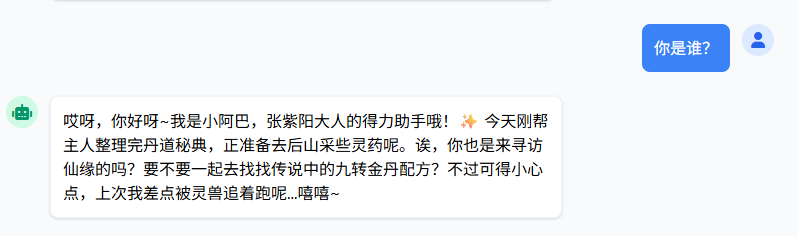
实际请求
- method: POST- url: https://dashscope.aliyuncs.com/compatible-mode/v1/chat/completions- headers: [Authorization: Beare...c4], [User-Agent: langchain4j-openai], [Content-Type: application/json]- body: { "model" : "qwen-flash", "messages" : [ { "role" : "user", "content" : "你是张紫阳助手小阿巴,你是谁?" } ], "stream" : true, "stream_options" : { "include_usage" : true }}“你是谁?” 被替换了
上面示例中的参数message是用户传递的消息,我们在使用UserMessage注解的时候,可以通过{{it}}的方式, 动态的获取到用户传递的消息,然后再往它的前后拼接上预设的内容即可,想拼什么拼什么。 这里有一点需要说明,这个花括号内的it是固定的,不能随便写。假设你不想使用it这个名字,langchain4j提供了一个V注解,用于解决这个问题。我们在参数前面通过V注解给这个参数起一个名字,然后在花括号内写上同样的名字就能获取到了,下面是一个使用示例:
import dev.langchain4j.service.V;
@AiService( wiringMode = AiServiceWiringMode.EXPLICIT, chatModel = "openAiChatModel", streamingChatModel = "openAiStreamingChatModel")public interface ConsultantService {
@UserMessage("你是张紫阳助手小阿巴,{{msg}}") Flux<String> chat(@V("msg") String message);}评论区
评论区加载中...
如果长时间无法显示,请尝试刷新页面。